MySQL基础
MySQL
MySQL基本语句
(2条消息) Mysql 最最最基本语句(大全)mysql数据库基础知识一个笨小孩哎呀的博客-CSDN博客
(2条消息) MySQL增删改查(基础)_朱wwww的博客-CSDN博客
MySQL中添加字段
1 | alter table car_evidence add `unit_name` varchar(64) comment '单位' |
MySQL中修改字段
1 | ALTER TABLE 表名 MODIFY COLUMN 字段名 字段类型 [属性]; |
MySQL中删除字段
1 | alter table 表名 drop column `unit_name`; |
case when 语句
1 | select name,case when (age > 60) then "老同学" |
if、ifnull的用法
1 | IF(expr1 , expr2 , expr3); |
MySQL连表查询的问题:
对于关联查询,以左关联为例,连接的条件是id,若右表的关联id为空,左表的id不为空,且左表的id为查询条件,仍能够查询 出左表需要的数据:
1 | select |
MySQL日期相关函数
1 | DATE(datatime) ---从精确到秒的日期格式中提取出年月日 |
GPT回答:
MySQL 中用于处理日期的函数有很多,下面是一些比较常用的函数及示例:
CURDATE()
功能:返回当前日期,去掉时间部分。
示例:1
SELECT CURDATE(); -- 返回 2021-12-19
CURRENT_DATE()
功能:也返回当前日期,去掉时间部分,与 CURDATE() 的作用相同。
示例:1
SELECT CURRENT_DATE(); -- 返回 2021-12-19
NOW()
功能:返回当前日期和时间。
示例:1
SELECT NOW(); -- 返回 2021-12-19 08:34:17
DATE_FORMAT(date,format)
功能:对日期进行格式化处理,返回一个指定格式的字符串。
示例:1
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s'); -- 返回 2021-12-19 08:34:17
DATE_ADD(date, INTERVAL value unit)
功能:给指定的日期添加一个时间间隔。
示例:1
SELECT DATE_ADD('2021-12-19', INTERVAL 1 DAY); -- 返回 2021-12-20
DATE_SUB(date, INTERVAL value unit)
功能:从指定的日期中减去一个时间间隔。
示例:1
SELECT DATE_SUB('2021-12-19', INTERVAL 1 MONTH); -- 返回 2021-11-19
DATEDIFF(date1, date2)
功能:计算两个日期之间的天数差。
示例:1
SELECT DATEDIFF('2021-12-19', '2021-11-19'); -- 返回 30
YEAR(date)、MONTH(date)、DAY(date)
功能:分别返回指定日期的年份、月份、日期。
示例:1
SELECT YEAR('2021-12-19'), MONTH('2021-12-19'), DAY('2021-12-19'); -- 返回 2021, 12, 19
更多 MySQL 日期函数的介绍及使用可以参考 MySQL 官方文档:Date and Time Functions
Mysql中的字段拼装及换行
1 | select |
通过GROUP_CONCAT()函数,可以将某个分组下的指定字段进行拼接,整合成一个字段
1 | select |
MySQL去重
mysql去重之distinct
distinct只能放在查询的最前面,且会根据查询的所有字段去重,如查询字段为A、B、C 那么只有当A、B、C完全相同时才会 选择一条,单单只是A、B相同不会进行去重;
mysql去重之group by
使用group by能够弥补distinct的不足,可以根据group by后面的字段进行去重,即group by后面是A、B,查询的字段是A、B、C,则只要A、B相同就会去重
MySQL类型转换及对索引的影响
Mysql在where查询条件中会自动对数据类型进行转化,但是这个转化涉及到的性能消耗还是比较高的,当然,在mybatis中也会自动对传入的参数进行转化(我好像没有看到他转化),从而减小mysql参数转换的消耗,那么Mybatis是如何进行参数转换的呢?待学习
特别注意,在MySQL进行隐式转换时,有可能会导致索引失效,这个在写代码时一定要考虑到!
MySQL连接语句及查询条件
sql语句的执行顺序:sql语句执行顺序并不是顺序的,而是按以下顺序进行:from —》where—》group by—》聚合函数—》having—》select—》order by
关于join on 后面所跟的查询条件,在只是内关联查询时是相同的,即A join B on 条件1 and 条件2 and 条件3 与A join B on 条件1 where 条件2 and 条件 3的效果是相同的。
但是在left join 与right join 时,条件在on后面与在where后面是不同的,因为在on后面,则不论条件是否成立,主表的数据一定能够查询到,而在where后面,两张表中不满足条件的数据都不会被查到。
如下sql
1 | select |
MYSQL常见报错
1 | 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'learning.content_test.send_time' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by |
子查询
列子查询
子查询返回的结果是一列多行
1 | select * from emp where salary > all ( select salary fron emp where dept_id = (select id fron dept mhere nane=‘财务部')》)); |
列子查询一般用到: in,比较符号,all 等
行子查询
子查询返回的结果是一行多列
1 | select * from emp where (salary , managepid)=(select salary,managerid from emp where nane =‘张无忌 ); |
表子查询
子查询返回的结果是一张表
1 | select e.*,d.* from (select * from emp where entrydate > '2806-81-01') e |
多表连接查询:inner join(自然连接,只加载符合查询结果的值,不会有空值) 与outer join(一般是left join 与right join,outer可以省略,left join即保留左边那个表的全部,右边可能有空值)
开窗函数
开窗函数的格式:SUM(计算字段名) OVER (PARTITION BY 分组字段名)
1 | #假设有一个学生表 student,包含以下字段:id(学号)、name(姓名)、age(年龄)、score(分数)、class_id(班级编号)。请你编写一个 SQL 查询,返回每个学生的详细信息(字段顺序和原始表的字段顺序一致),并计算每个班级的学生平均分(class_avg_score) |
MySQL默认的隔离级别
(29条消息) mysql四类隔离级别mysql默认事务隔离级别和光同尘ss的博客-CSDN博客
四类隔离级别:




存储引擎
存储引擎是作用到表上的
查看存储引擎
1 | show engines; |
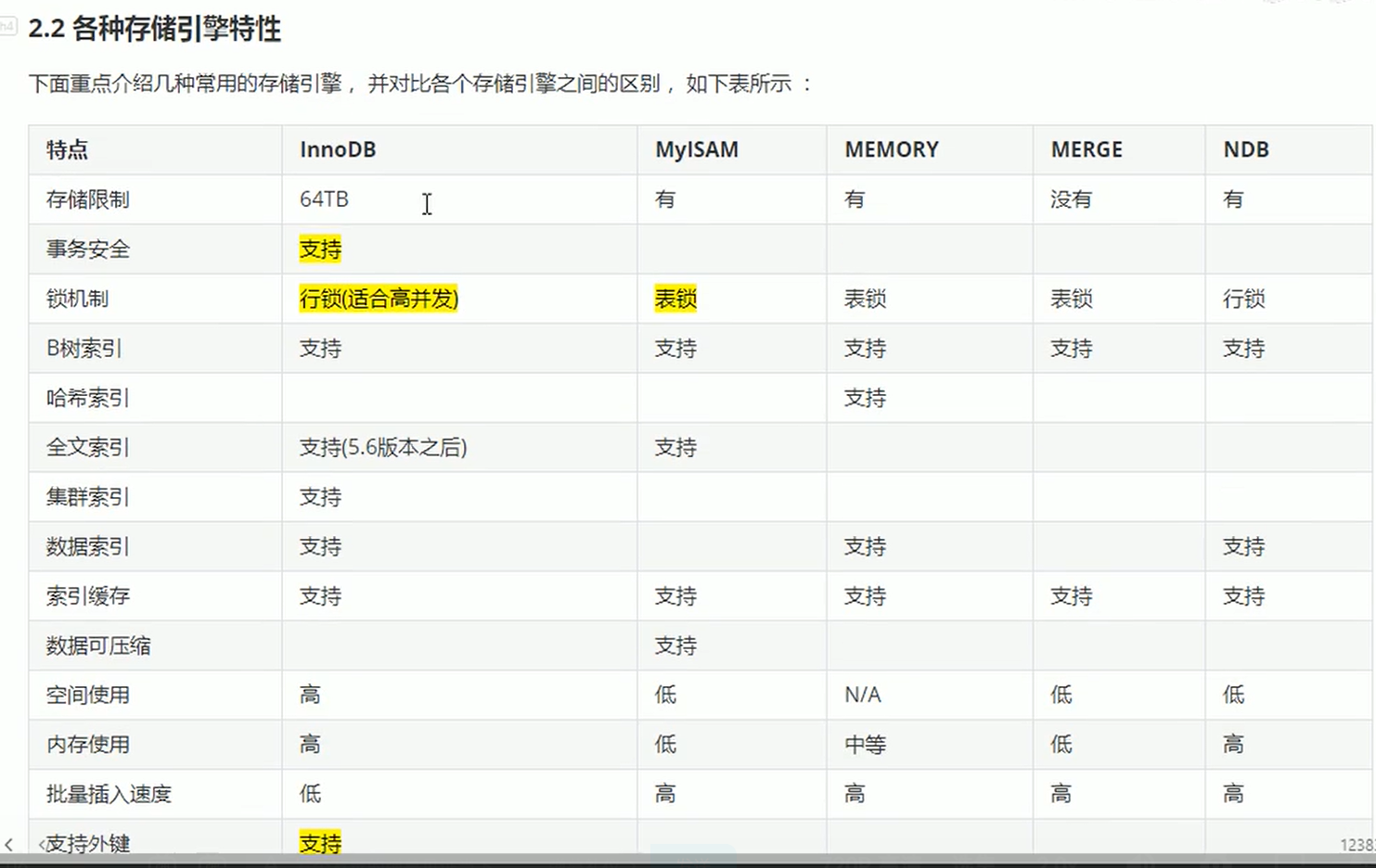
InnoDB特性
- 事务控制(需要提交事务才能够完成事务)
- 支持外键约束
- 一般是聚合索引

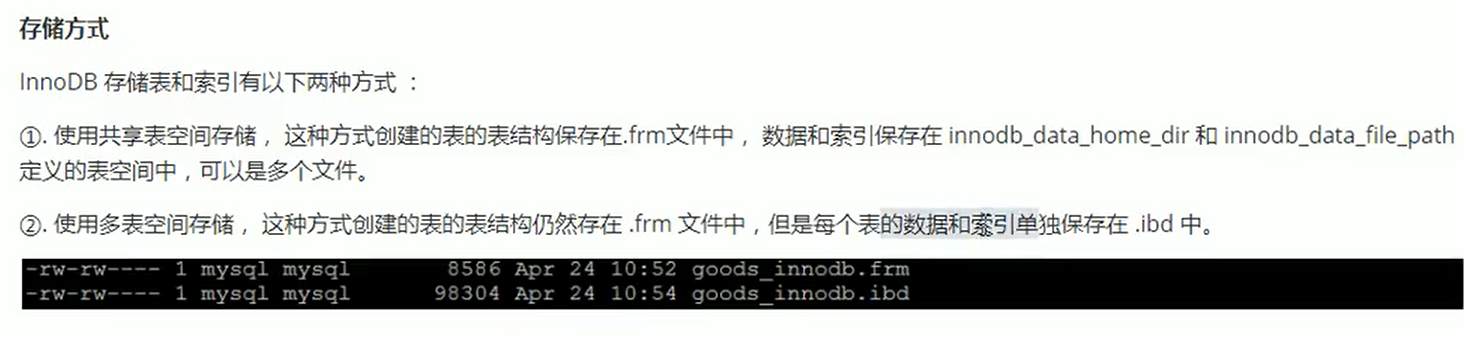
存储方式:

数据库锁
全局锁:对整个数据库实例加锁,后续的DML、DDL语句以及更新事务的提交都将会被阻塞。一般用于全库的逻辑备份。(保证备份数据的一致性)
使用方式:
1 | flush tables with read lock; |
不加全局锁的一致性备份方式:
1 | mysqldump -single-transaction -uroot -p12345678 heima>D:/heima.sql |
表级锁:
- 表锁
- 表共享读锁 read (其他客户端包括自己都不能修改表中的内容,会被阻塞,但是能够读取数据)
- 表独占写锁 write(其他客户端都不能修改表中的内容,会被阻塞,也不能读取数据;当前客户端可以做所有操作)
- 加锁方式 :lock table ‘表名’ read/write
- 释放锁:unlock tables
- 元数据锁(MDL)
- 该锁的存在是为了避免DML语句与DDL语句的冲突,在表中存在事务时,不可对元数据(表结构)进行操作
- 当对表进行增删改查时会自动加上MDL读锁,对表结构进行更改时,会自动加上MDL写锁
- 意向锁
- 为了解决在执行DML语句时,其他线程要对该表进行加锁,避免行锁与表锁之间的冲突,通过意向锁来减少表锁的检查。当线程A执行DML语句(如update)时,会在加上行锁的同时加一把意向锁。此时线程B加表锁时会先去判断是否被意向锁所兼容,若不兼容则阻塞
- 意向共享锁(IS);由语句 select … lock in share mode 添加 与表锁排他锁互斥
- 意向排他锁(IX);由语句 inseet\delete\update\select … for update 添加
行级锁:
进行行锁测试时要开启事务来进行测试
注意:InnoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,InnoDB会对表中所有记录加锁,升级为表锁。
- 行锁
- 共享锁(S):允许一个事务读一行,阻止其他事务获取排他锁;(其他事务可以读)
- 排他锁(X):允许获取排他锁的事务更新数据,组织其他事务获取相同数据集的共享锁、排他锁(其他事务啥也不能做)
- 间隙锁
- 间隙锁的唯一目的就是防止其他事务插入间隙,间隙锁可以共存,一个事务采用间隙锁,不会阻止其他事务在同一间隙上采用间隙锁
- 临键锁
- 索引上的等值查询给不存在的记录加锁时优化为间隙查询
按性质主要分为悲观锁和乐观锁
- 乐观锁(Optimistic Locking):
- 乐观锁是一种不直接锁定数据的机制,它假设不会有并发冲突,只有在提交事务时才会检查是否有冲突,如果有则进行回滚或重试。
- 示例:假设某个表中的一列表示库存数量,事务A读取该列并更新库存数量,然后提交事务。在提交时,事务A会检查库存数量是否发生变化,如果无变化则提交成功,否则回滚或重试。
- 悲观锁(Pessimistic Locking):
- 悲观锁是一种在操作数据时直接锁定数据的机制,即使没有并发冲突也会锁住数据,这样其他事务无法对数据进行操作。
- 示例:假设某个表中的一列表示库存数量,事务A读取该列并锁定数据,然后执行更新与提交事务。在事务A提交之前,其他事务无法读取或更新该列。
行锁和页锁适用于并发度高、冲突少的情况;表锁适用于并发性较低的情况;乐观锁适用于并发度高、冲突少、读多写少的情况;悲观锁适用于并发度高、冲突多、写多读少的情况。
索引
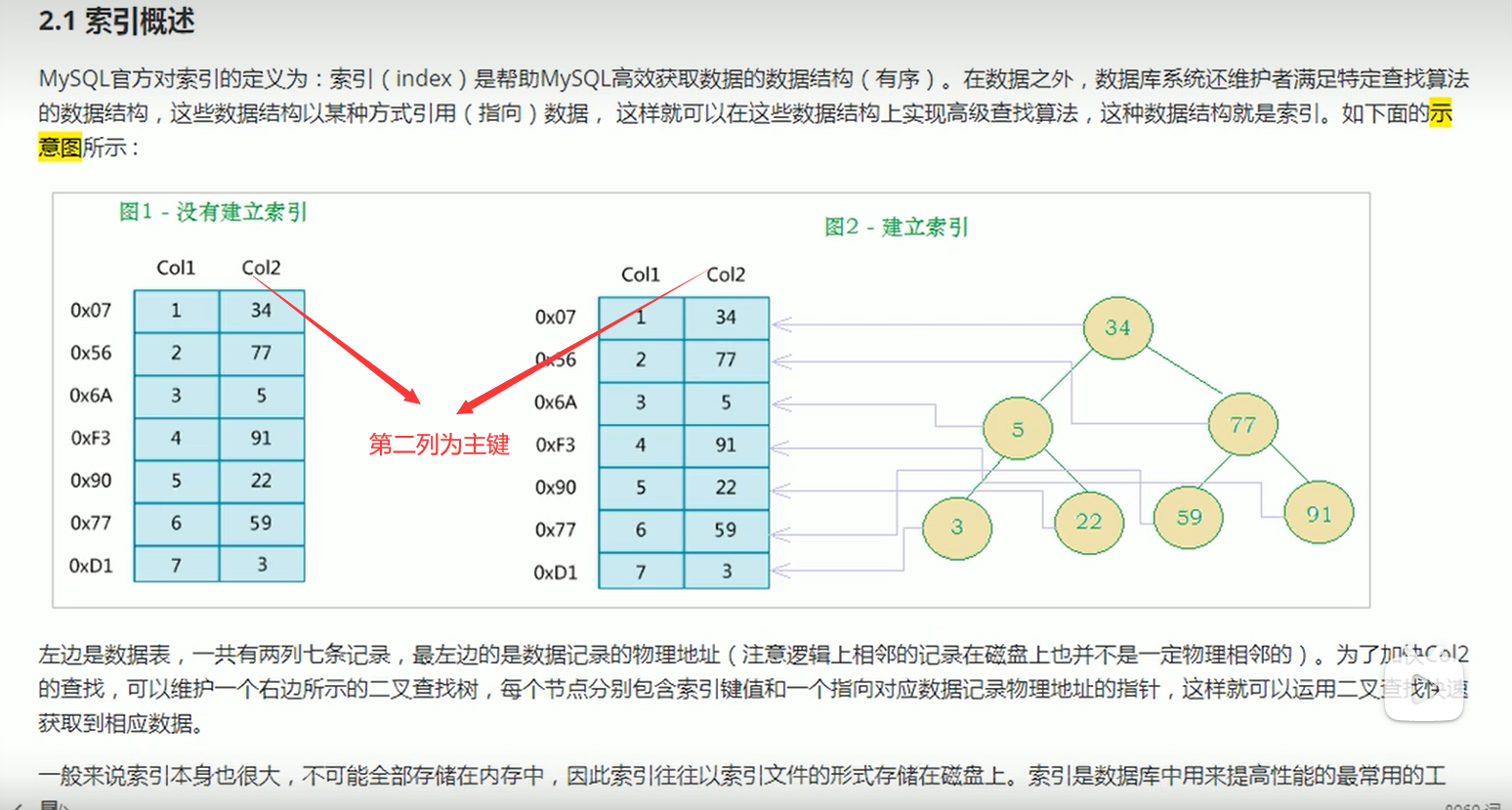
索引是一种帮助我们更快查找到数据的方法,索引的基本语法:创建、修改、删除、查询,索引生效的前提是要有序
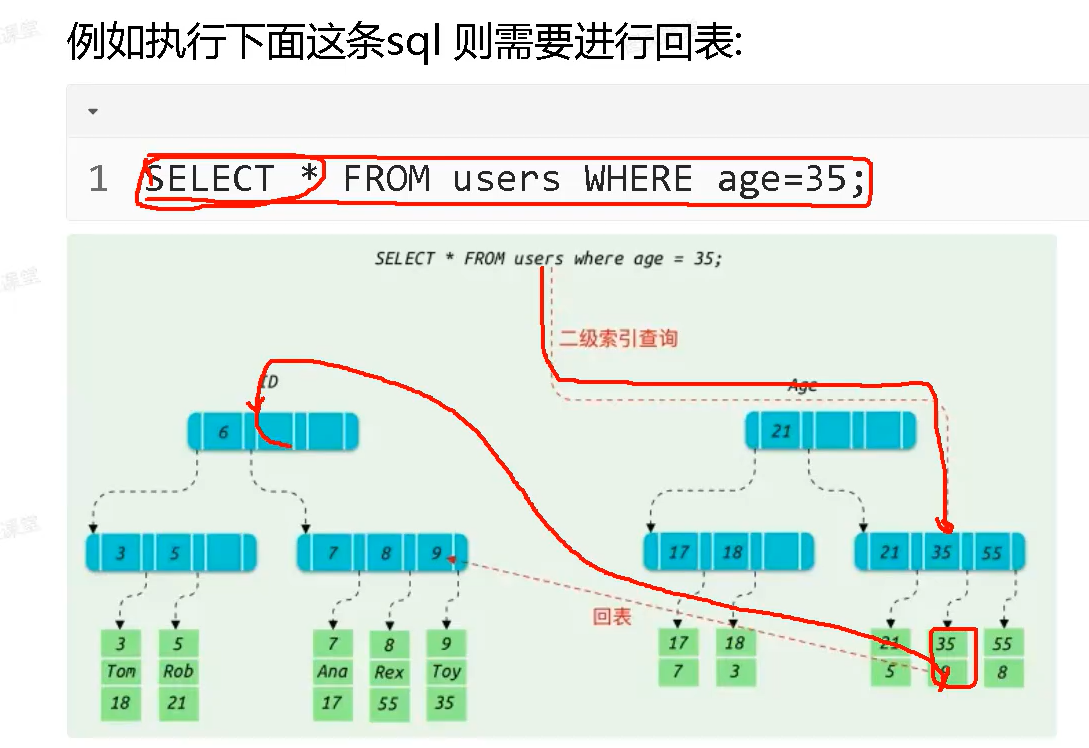
索引分为一级索引和二级索引,一级索引含有一条记录的全部数据,二级索引含有一级索引的index,同时二级索引也是引起回表的原因
索引分类:
1.普通索引(normal index):最基本的索引类型,没有任何限制。
2.唯一索引(unique index):与普通索引类似,但是列中的值必须唯一。
3.全文索引(full-text index):只能用于myisam表,用于全文搜索。
4.主键索引(primary key index):特殊的唯一索引,用于标识表中每行数据的唯一性。
5.联合索引(composite index):将多个列组合成一个索引,可以提高查询效率。
6.空间索引(spatial index):特殊的索引类型,用于处理包含空间数据类型的列。
索引结构
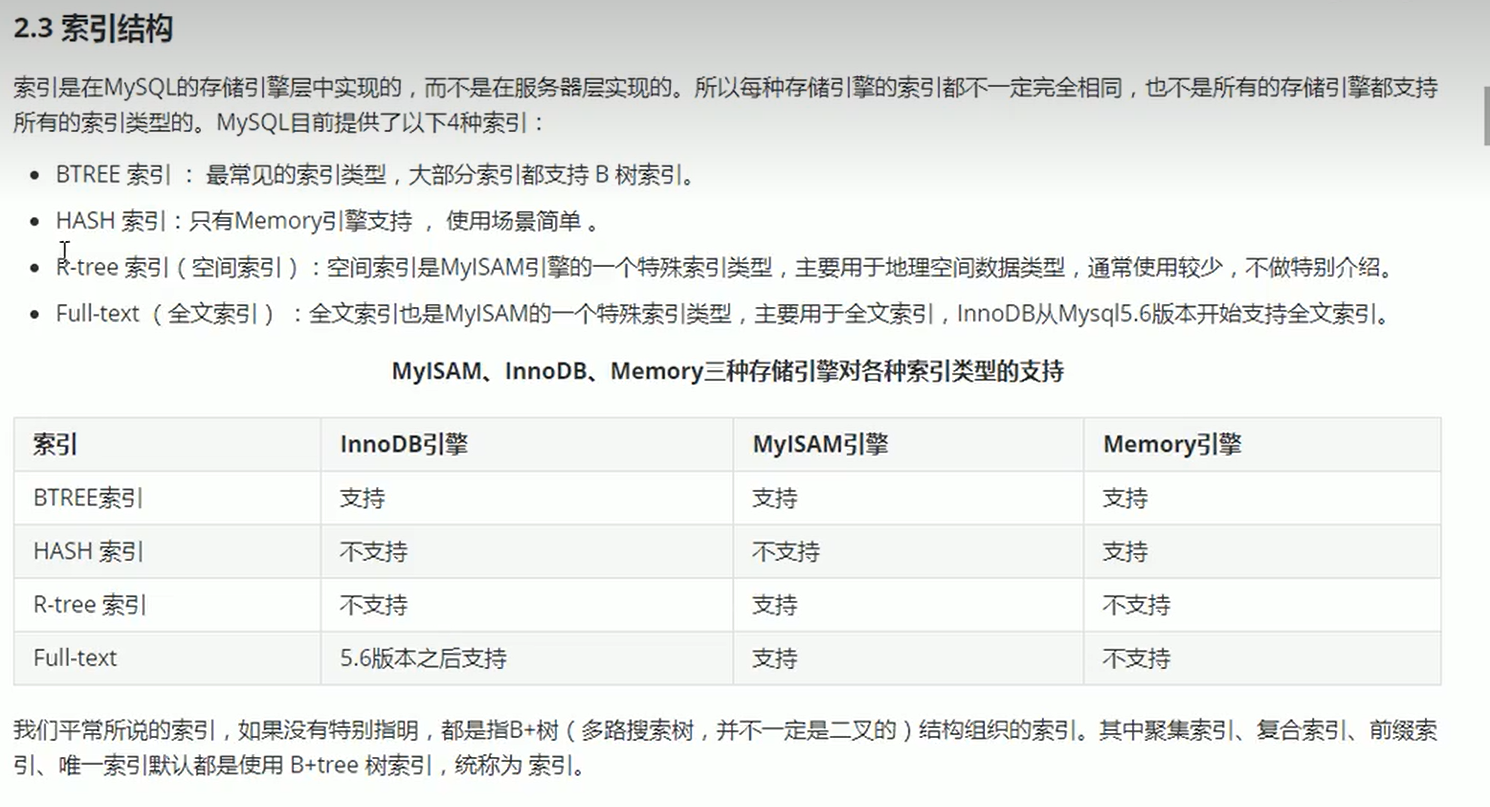

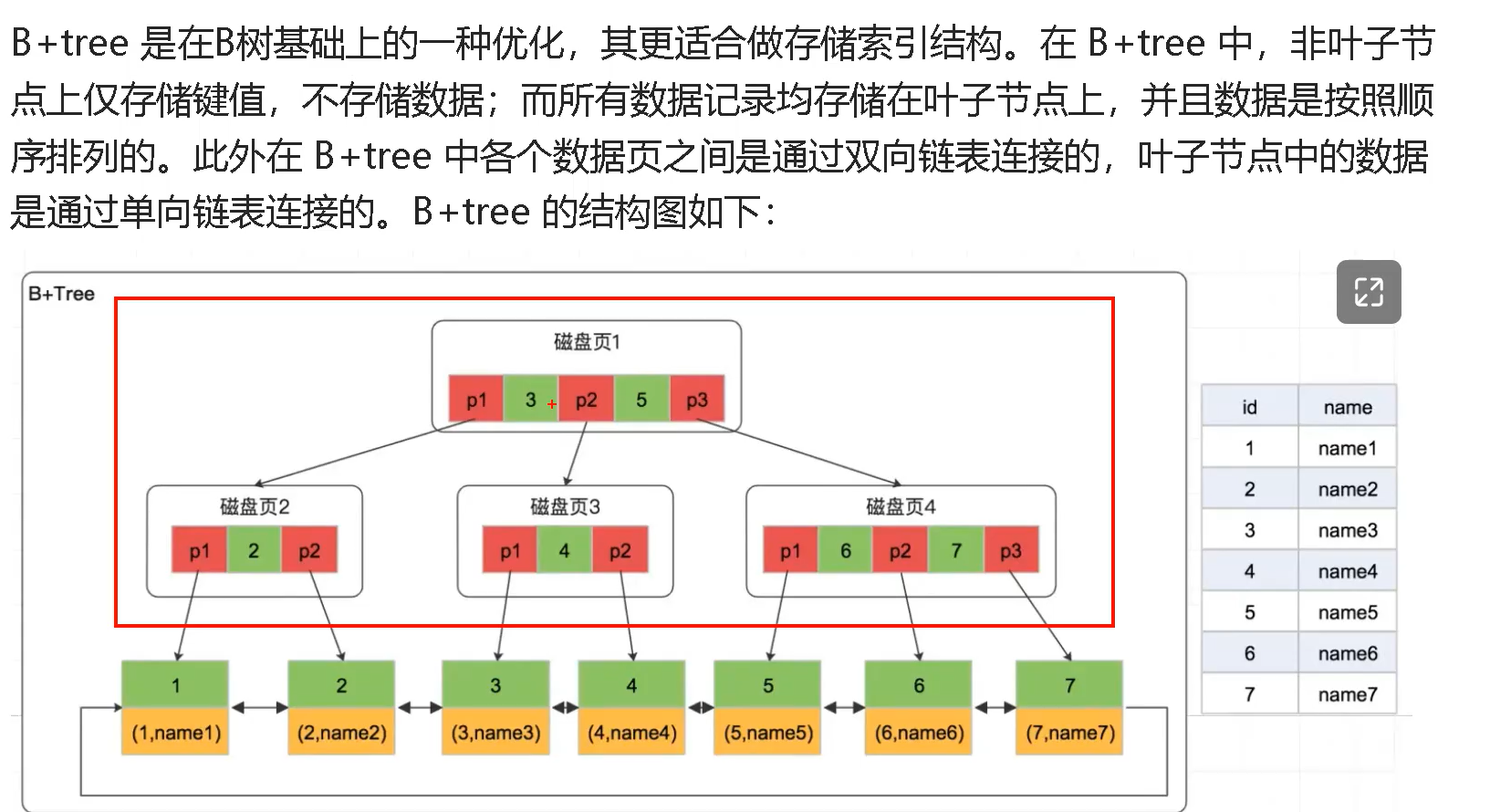
B+树
索引的底层结构是B+树,若一个表未创建主键索引,也会创建B+树(将rowid做为主键索引)
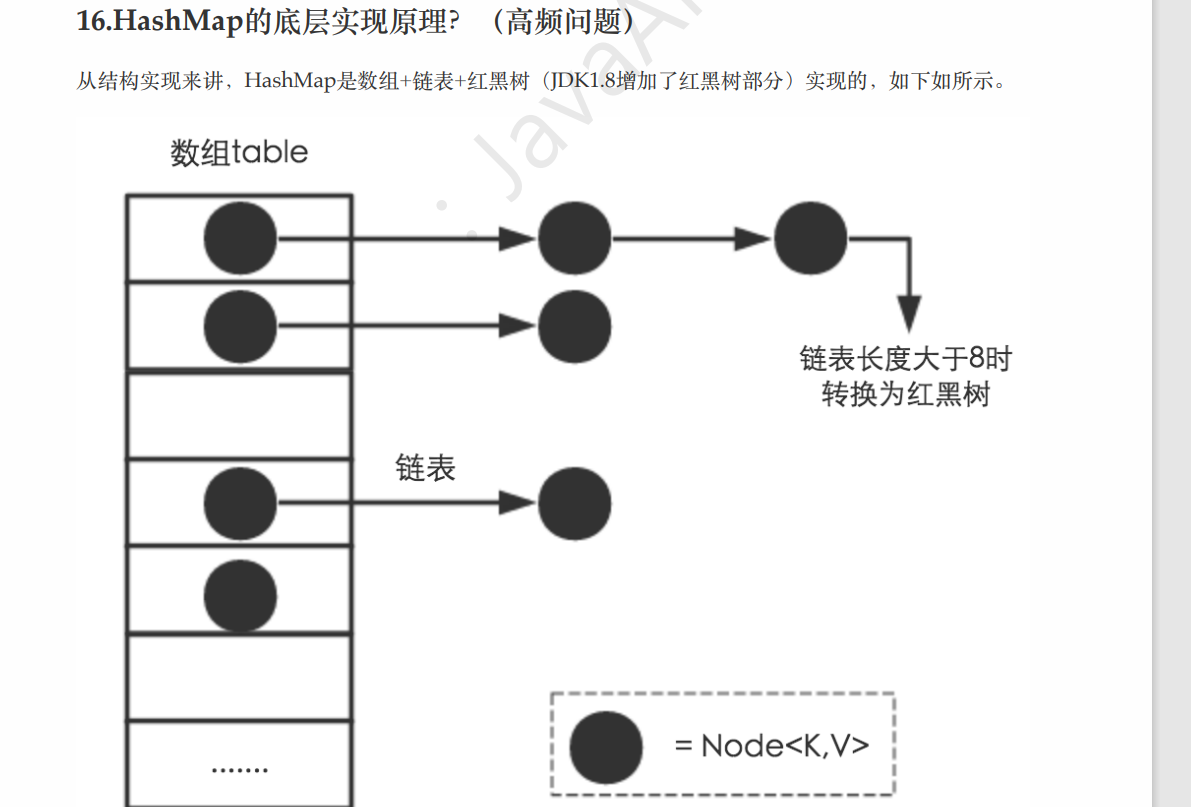
Hash索引
Hash索引一般只用于等值比较,查询的效率是非常高的,但是不适用于范围查询也不支持排序。
补充HashMap的底层原理,来更容易理解Hash
map的底层数据结构!!(通过散列key来存储键值对)
1、key通过运算得到一个值,通过这个值将key-value键值对存入该值对应的位置
2、hashmap处理重复元素的方法是通过新的value来覆盖旧的value

聚合索引和非聚合索引
所有非主键索引都可以称之为二级索引
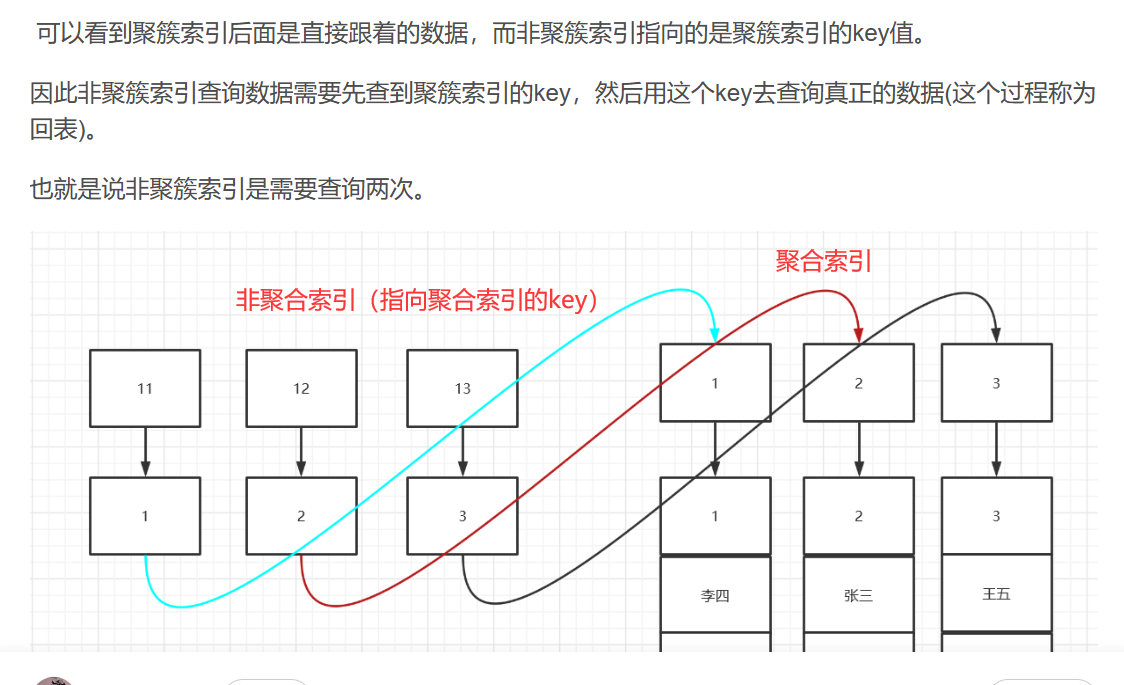
回表
索引覆盖
减少了回表的一些情况

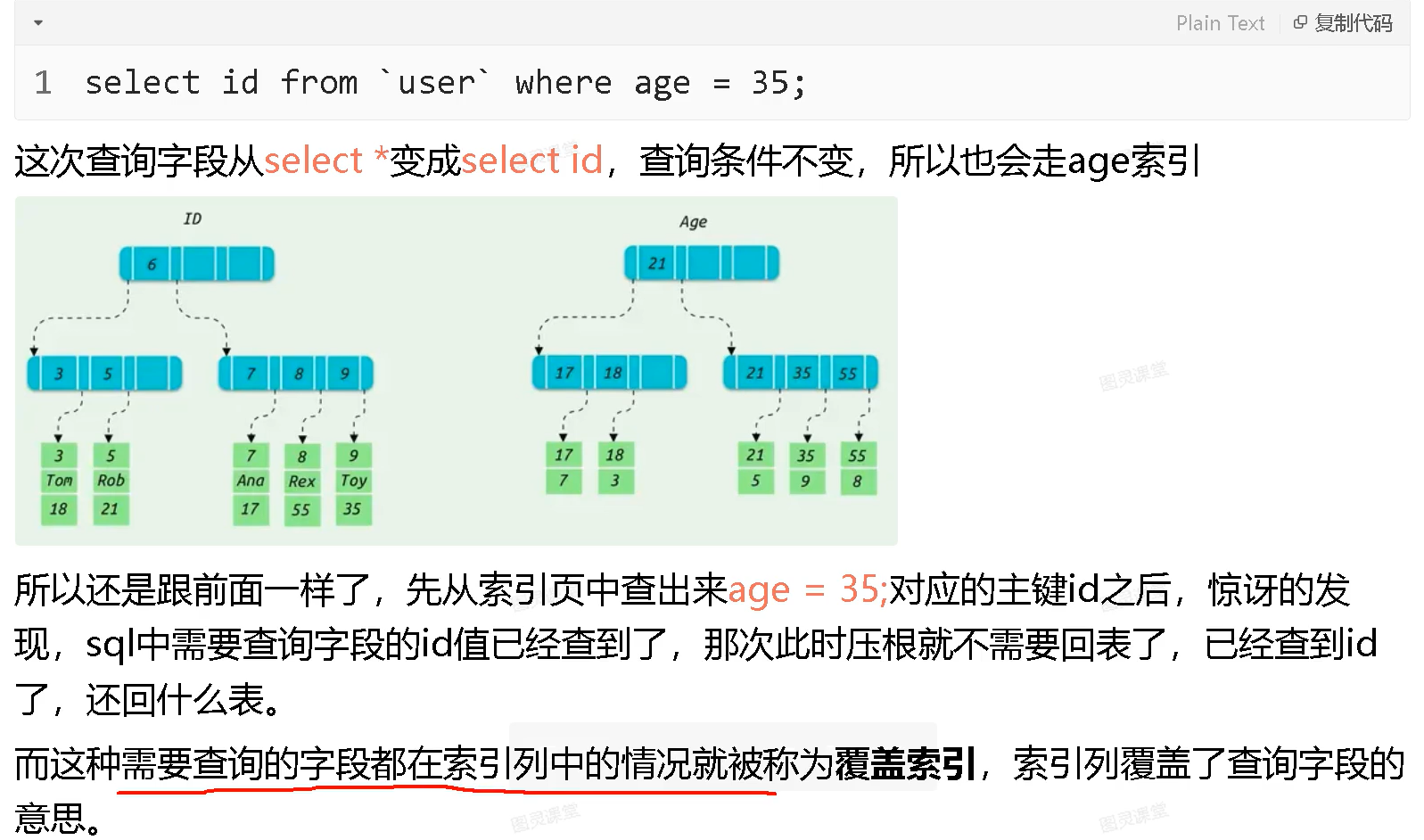
ps:联合索引查询时,若是多个字段用and连接,那么只要存在最左字段,其位置在哪都可以,因为mysql会在查询时帮我们进行优化,但是最好还是我们自己把该字段写在最左边!
索引下推(ICP)
对于二级索引的优化,减少范围查询时的回表次数
即根据二级索引查找到数据后一次性全部回表,不在一次一次的回表(如何一次性全部回表呢?)
索引设计原则

最左前缀原则就是为了使联合索引能够生效,即在查询时一定要将所创建的联合索引最左边的那个字段包含,且在最前面。
联合索引的适用场景:联合索引能够减少开销,有利于索引的覆盖(当查询的字段都属于联合索引时,能够很快定位到所需查询的位置,不需要再次回表,此外在用联合索引进行查询时,不能够跳过索引列表中中间的几个字段,否则效率回降低!
联合索引中:带头大哥不能死,中间兄弟不能断
索引的优缺点
优点:
- 提高检索效率
- 降低排序成本,索引对应的字段会有一个自动排序的功能,默认是升序asc
缺点:
- 创建索引和维护索引需要一定的时间,且随着数据量的增大而增大
- 索引需要占用物理空间,数据量越大占用空间越大
- 会降低表怎删改的效率,每次增删改索引都需要进行动态维护
存储过程
存储过程是SQL语句的集合
分隔符修改

SQL优化
SQL的优化一般是在索引的基础上进行的优化
SQL优化的5个主要方法:
- 创建索引减少扫描量
- 调整索引减少计算量(in关键字后的内容过多也会导致查询时间过长)
- 索引覆盖(减少不必要的访问列,避免回表查询)
- 干预执行计划
- SQL改写
分析
1、查看各个语句的执行次数(提供优化的方向)
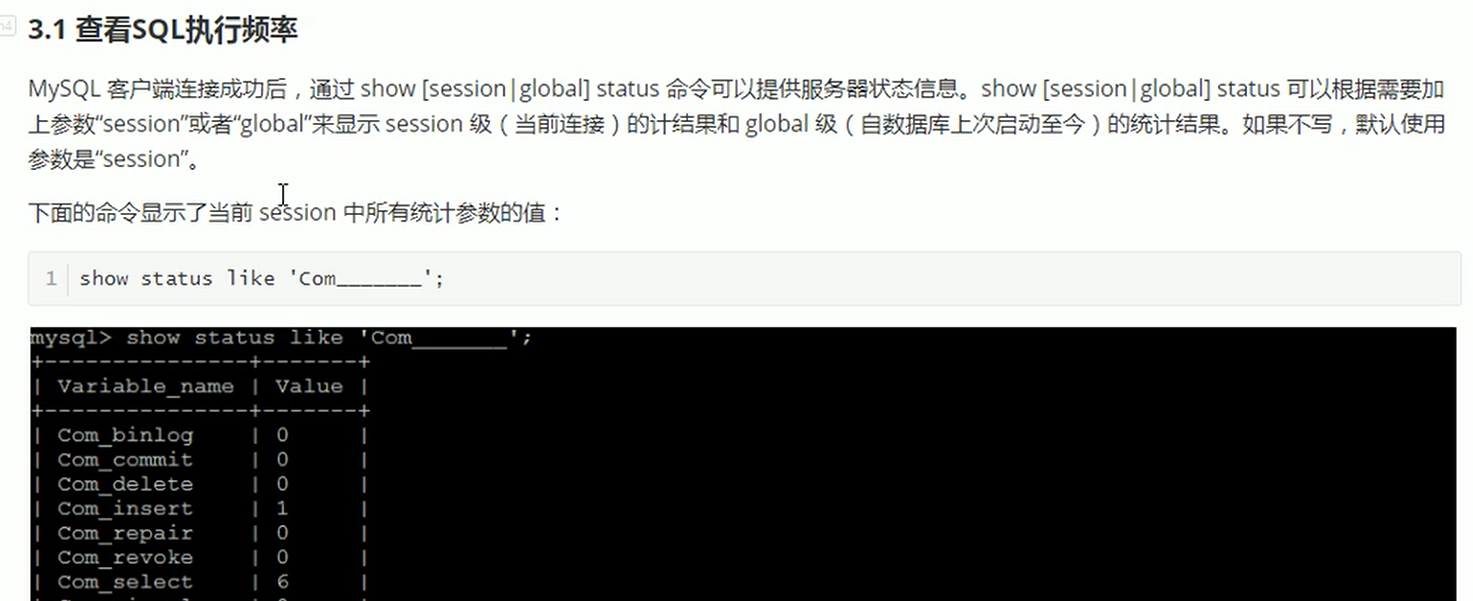
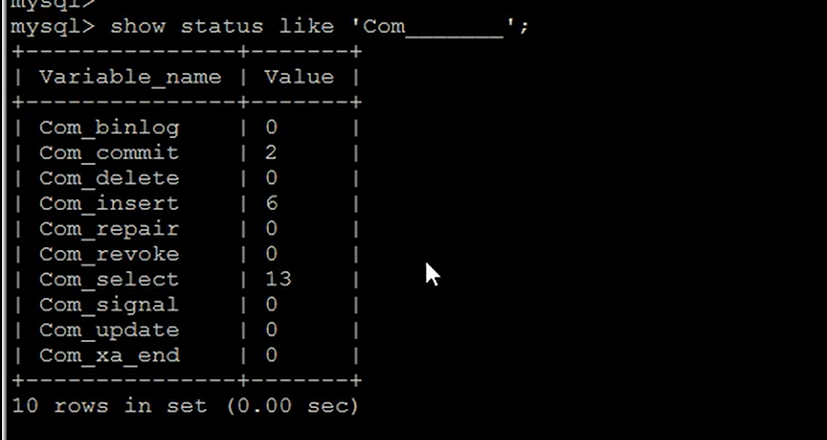
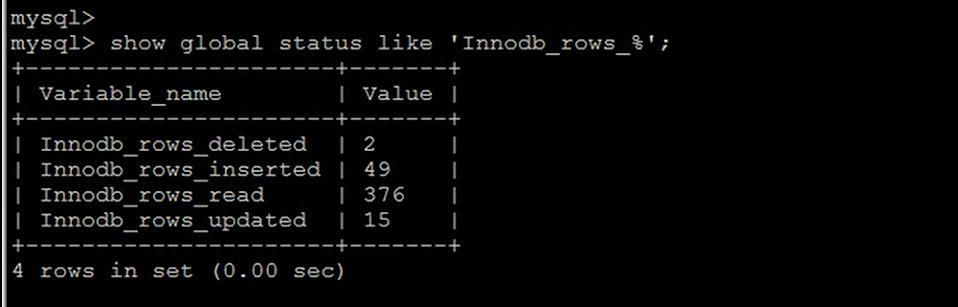
2、定位低效sql语句

通过 show processlist 可以看出当前数据库的状态,若某条语句正在进行,说明该条语句的性能就比较低了
3、分析语句,通过explain可以分析语句
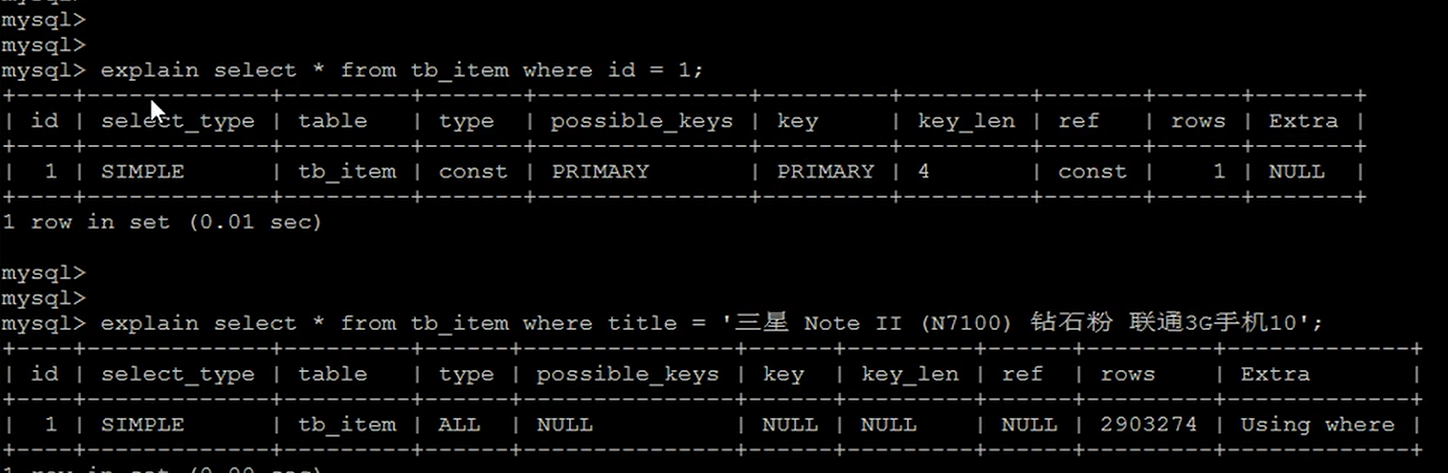
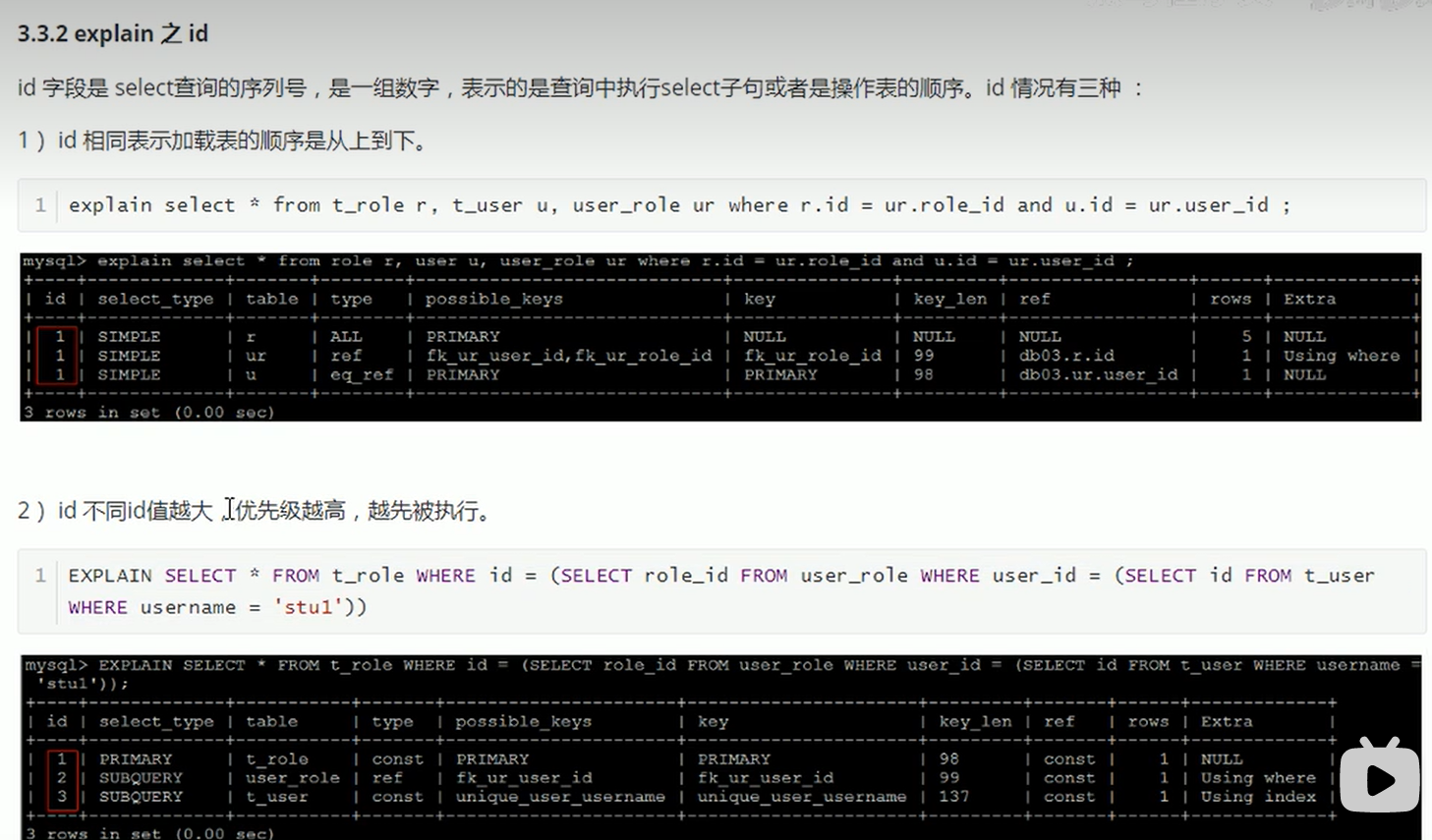

type字段决定mysql如何查找表中的数据,查找数据记录的大概范围。这个字段的所有值表示的从最优到最差依次为:
system > const > eq_ref (使用唯一索引进行查询)> ref(使用普通索引或者唯一索引的前缀部分进行查询) > range(使用范围查找) > index (扫描二级索引)> all;
trace工具

1 | set session optimizer_trace="enable=on",end_markers_in_json=on;//启动trace |
索引优化
索引生效的前提是要有序- 全值匹配
- 最左前缀原则
- 不要再索引列上做任何函数操作、计算操作、or操作、类型转化
- 若需要对索引列进行操作,尽量考虑用范围相关的操作,如like、>这些
- 存储引擎不能使用索引中范围条件右边的列
- 范围查询会使后面字段无序,造成部分索引失效
- 尽量使用覆盖索引(只访问索引的查询),减少select * 语句
- 不等号、空值、or会导致索引失效,要少用
- like的%写最右,因为前模糊的话一般要全部扫描了
- 字符串不加单引号也会导致索引失效
- 范围查询的优化(将大的范围拆分成多个小的范围)
补充:一般在explain的时候若有possible_keys可以使用FORCE_INDEX(索引名称)来强制使用索引
索引使用总结:
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
Like百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用;
VAR引号不可丢,SQL高级也不难!
SQL优化
- 不要使用select *
- 小表驱动大表:select 成绩 from 学生(数据少,为小表,主表) left join 成绩(数据多,为大表) on id = id
- 用连接查询代替子查询(具体情况具体分析)
- 提升group by 的效率(为group by的那个字段添加索引)
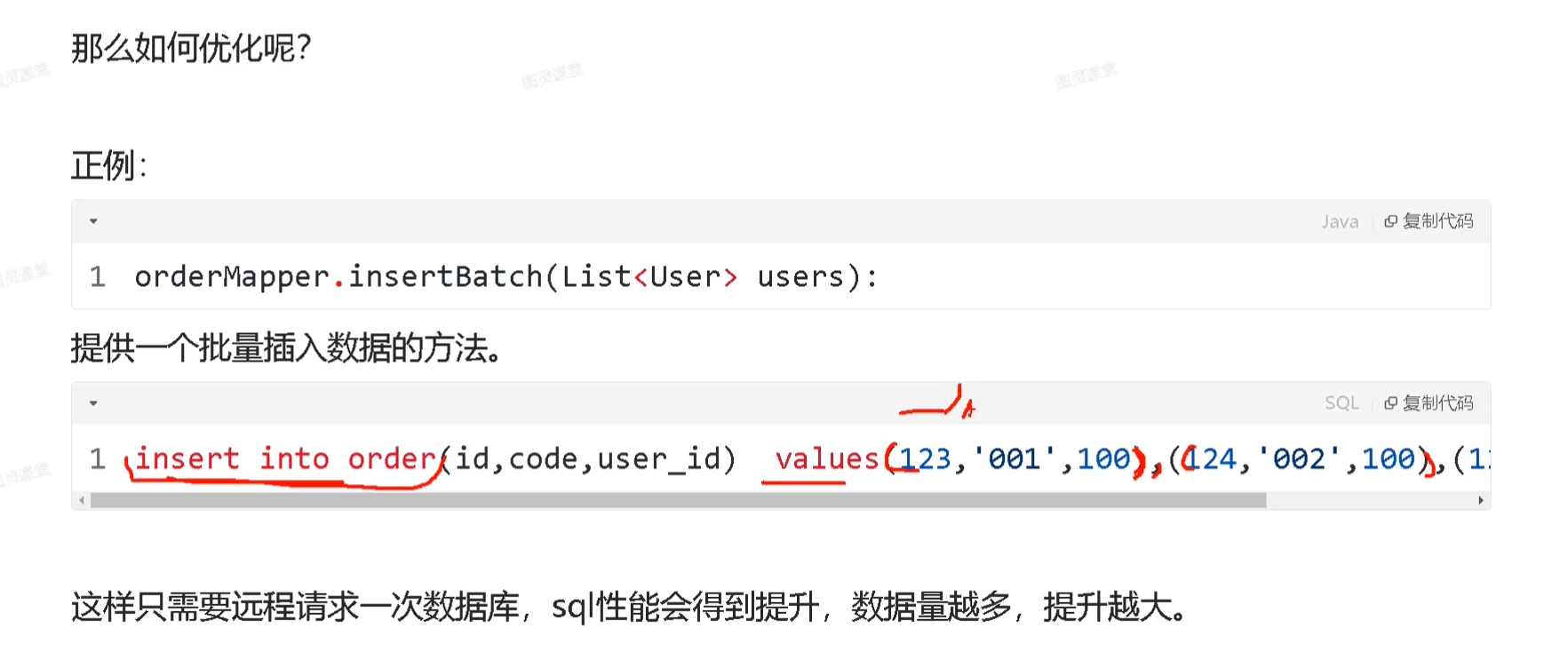
- 批量插入数据(即便是批量插入也建议控制一下数量,一次插入500作用就差不多了)
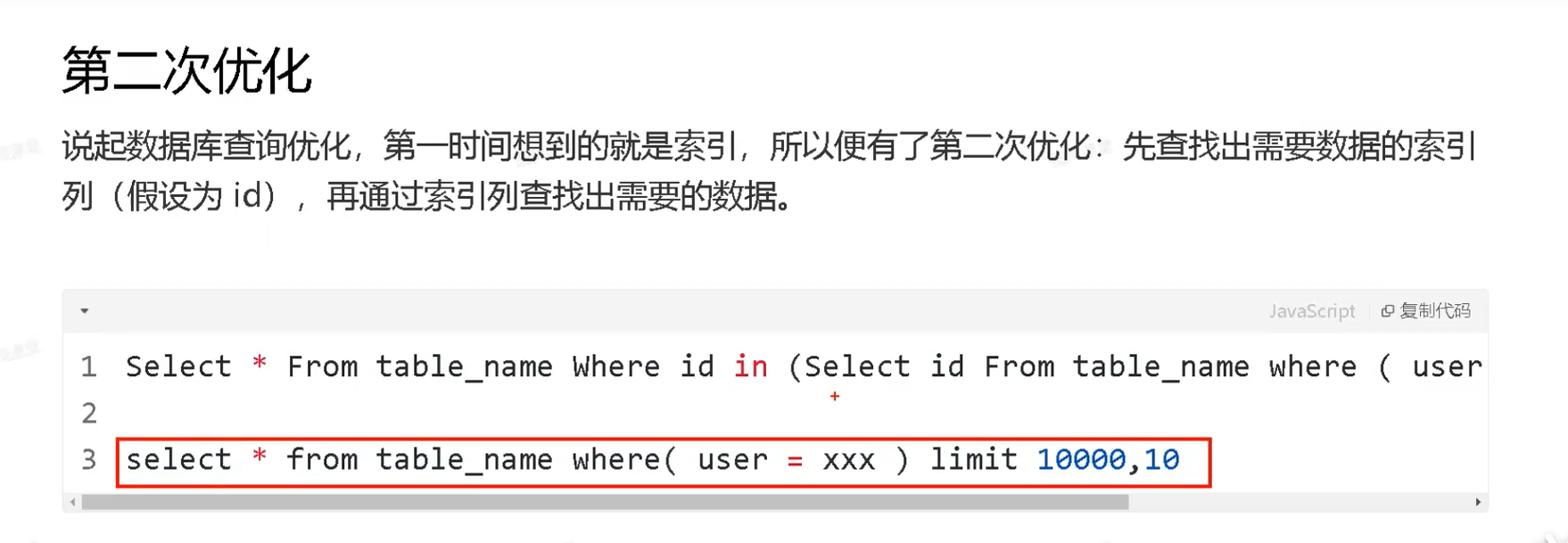
- 一次查询过多的话要使用limit(用Mybati的时候他有一个分页插件,会帮我们改写sql,所以在mapper文件中一般不需要写limit这种)
- 通过id来过滤查询的内容,利用主键查询提高效率(in那边还可以通过表连接再来提升一次效率)
- 用union all来代替union,因为union需要去重,会占用更多CPU资源
- join的表不宜过多
MySQL存储过程
1 | mysql> delimiter // |
delimiter是分隔符的意思,如果我们没有声明分隔符,编译器会把存储过程当成SQL语句进行处理,那么存储过程的编译过程会报错,所以事先要使用delimiter关键字声明当前分隔符(delimiter //),这样MySQL才会将“;”当做存储过程中的代码,不会执行这些代码。但记得用完之后要把分隔符还原(delimiter;)
调用存储过程:
MySQL 中使用 CALL 语句来调用存储过程。调用存储过程后,数据库系统将执行存储过程中的 SQL 语句,然后将结果返回给输出值。
CALL 语句接收存储过程的名字以及需要传递给它的任意参数,基本语法形式如下:
1 | CALL sp_name([parameter[...]]); |
其中,sp_name 表示存储过程的名称,parameter 表示存储过程的参数。
MySQL分库分表
数据的分库分表分区,中心思想都是是使得单一数据库/数据表的数据量变小,来缓解单一数据库的性能问题。
拆分策略:
- 垂直分库:以表为依据,不同的表分到不同的库中,每个库中的表结构不同,数据不同
- 垂直分表:以字段为依据,不同的字段拆分到不同的表中,每个表的结构不同,数据不同(通过主键关联)
- 水平分库:以字段为依据,将一个库的数据拆分到不同的库中,每个库的表结构相同,数据不同
- 水平分表:以字段为依据,将一个表中的数据拆分到其他数据库表中,每个表的结构相同,数据不同


分库分表实现的技术:
- shardingJDBC:基于AOP思想,在sql前进行拦截,性能较好
- MyCat:中间件,不同调整代码,性能较差
MySQL分区
表分区是将一个大表,分成若干个小表,一般根据日期将表进行分区,分区表在查询过程中一定要注意要带有分区字段作为查询条件,若是关联查询,则两个表的分区字段都需要带上。
分区的策略:
- range分区
- list分区(可以有效的帮我们进行一些挑选分区)
- hash分区(分布比较均匀)
基本SQL及相关操作语句练习
1 | select s.user_id, round(sum(if(c.action="confirmed", 1, 0))/count(*), 2) confirmation_rate |
570. 至少有5名直接下属的经理 - 力扣(LeetCode)
1 | select a.Name |
练习题:
(2条消息) MySQL学习:50道经典题目(含参考答案)(更新中)_mysql考试试题_Ghost_pepper的博客-CSDN博客
