Mybatis基础知识 Mybatis配置文件 特别注意 :在idea的resource下要建目录的话必须采用com/hui/mybatis/mapper的形式,不能是com.hui.mybatis.maper的形式,因为resource目录与java目录不同,没有“包”的概念!!!
### 配置文件层级关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd" ><configuration > <properties /> <settings /> <typeAliases /> <typeHandlers /> <objectFactory /> <plugins /> <environments > <environment > <transactionManager /> <dataSource /> </environment > </environments > <databaseIdProvider /> <mappers /> </configuration >
configuration中的配置一定要按这个顺序进行配置,否则会报错
Mapper中的namespace的作用:为了防止不同mapper.xml文件之间相应id的冲突,在面向接口编程时,namespace指向的是所对应的那个mapper的全路径,如下:
1 <mapper namespace ="com.huihui.server.mapper.UmRoleMapper" >
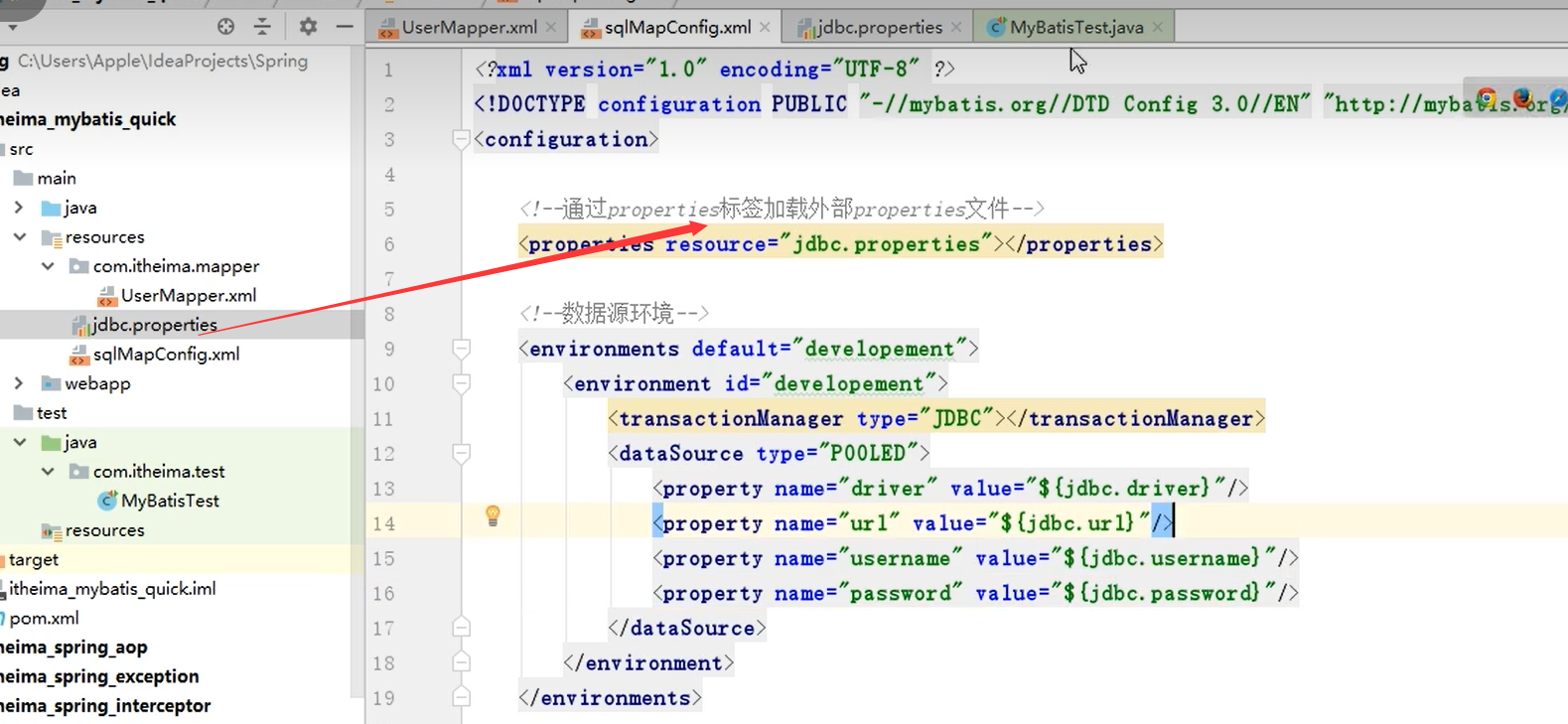
外部文件加载
数据库连接池 1 2 3 4 5 6 7 8 9 10 11 <environments default ="development" > <environment id ="development" > <transactionManager type ="JDBC" /> <dataSource type ="POOLED" > <property name ="driver" value ="com.mysql.jdbc.Driver" /> <property name ="url" value ="jdbc:mysql://localhost:3306/cloud-user?serverTimezone=UTC" /> <property name ="username" value ="root" /> <property name ="password" value ="1234567" /> </dataSource > </environment > </environments >
连接池的好处
控制连接对象的创建数量、防止服务器宕机
每次获取连接都从池中拿,效率高
别名 在核心配置文件中定义别名后,各个映射文件也能使用别名(别名中不区分大小写,但是namespace没有别名机制)
1 2 3 4 5 <typeAliases > <package name ="com.huihui.form" /> <package name ="com.huihui.dto" /> </typeAliases >
idea中还可以为Mybatis核心配置文件、mapper文件设置模板
Mybatis配置文件参考:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd" > <configuration > <properties resource ="jis.properties" /> <settings > <setting name ="logIml" value ="STDOUT_LOGGING" /> <setting name ="mapUnderscoreToCamelCase" value ="true" /> </settings > <typeAliases > <package name ="com.huihui.form" /> </typeAliases > <plugins > <plugin interceptor ="com.github.pagehelper.PageInterceptor" /> </plugins > <environments default ="development" > <environment id ="development" > <transactionManager type ="JDBC" /> <dataSource type ="POOLED" > <property name ="driver" value ="${driver}" /> <property name ="url" value ="${url}" /> <property name ="username" value ="${username}" /> <property name ="password" value ="${password}" /> </dataSource > </environment > </environments > <mappers > <package name ="com.huihui.server.mapper" /> </mappers > </configuration >
mapper文件
mapper文件中主要是写各种SQL语句
插入数据 mybatis默认不提交事务!!(通过sqlSession.commit手动提交)
插入数据时如何获取数据库自动生成的主键值?
1 2 3 4 //useGeneratedKeys 获取生成的主键值 keyProperty="id" 生成的主键值要赋值的对象 <insert id ="insertUser" useGeneratedKeys ="true" keyProperty ="id" > insert into tb_user values(#{id},#{username},#{address}) </insert >
若插入的是map集合,则#{ }里面写的是map集合的key;一般mybatis中入参类型可以不写
1 2 3 <insert id ="insertUser" parameterTpye = "map" > insert into tb_user values(#{id},#{username},#{address}) </insert >
插入多参数 时mybatis底层是以map的形式存放的,map.put("arg0",name), map.put("arg1",sex);
同时也可以通过@Param注解的形式来区分多个入参,便于阅读
在语句中也需要使用arg0来获取参数,arg0、arg1的顺序与传入的参数的顺序一致
1 2 <insert id ="insertUser" > insert into tb_user values(#{arg0},#{arg1},#{arg2}) </insert >
1 INSERT INTO user_list VALUES (1 ,"huiihui","shuai"),(2 ,"huiihui","shuai"),(3 ,"huiihui","shuai"),(4 ,"huiihui","shuai");
1 2 3 4 5 6 7 8 9 10 11 12 13 <insert id ="insertBatch" > INSERT INTO role_info VALUES <foreach collection ="cars" item ="car" separator ="," > (null,#{car.carName},#{car.brand},#{car.produceTime}) </foreach > </insert > <insert id ="insertBatch" > INSERT INTO role_info VALUES <foreach collection ="cars" item ="car" open ="(" separator ="," close =")" > null,#{car.carName},#{car.brand},#{car.produceTime} </foreach > </insert >
特别注意 Mybatis在进行查询操作时要注意查询出的列要由别名,否则会和定义的实体类无法匹配从而出现null!!

### 动态SQL
官网链接:[动态 SQL_MyBatis中文网](https://mybatis.net.cn/dynamic-sql.html) mapper中还可以对SQL进行收取,达到复用
### 补充
java中获取时间:
要在Java中获取当前日期和时间,可以使用以下步骤:
1. 导入`java.time`包中的相关类,这是Java 8及以上版本的日期和时间API。
1 2 3 4 import java.time.LocalDate; import java.time.LocalTime; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter;
1 2 LocalDate currentDate = LocalDate.now();System.out.println(currentDate);
1 2 LocalTime currentTime = LocalTime.now();System.out.println(currentTime);
1 2 LocalDateTime currentDateTime = LocalDateTime.now();System.out.println(currentDateTime);
1 2 3 DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss" );String formattedDateTime = currentDateTime.format(formatter);System.out.println(formattedDateTime);
Mybatis的事务管理机制
mybatis中有两种事务管理器:JDBC、MANAGED
1 2 3 4 5 6 7 8 9 10 11 12 <environments default ="development" > <environment id ="development" > <transactionManager type ="JDBC" /> <dataSource type ="POOLED" > <property name ="driver" value ="com.mysql.jdbc.Driver" /> <property name ="url" value ="jdbc:mysql://localhost:3306/cloud-user?serverTimezone=UTC" /> <property name ="username" value ="root" /> <property name ="password" value ="1234567" /> </dataSource > </environment > </environments >
mybatis采用原生的JDBC自己管理事务
connection.setAutoCommit(false) 开启事务
connection.commint()手动提交
mybatis不再管理事务,交给其他容器负责,如Spring
Mybatis高级映射 多对一映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Data public class Student { private long sid; private String sName; private long cid; private Clazz clazz; } @Data public class Clazz { private long cid; private String cname; }
1 2 3 4 5 6 7 8 <select id ="selectById" resultMap ="studentResultMap" > SELECT s.id,s.name,c.cid,c.cname FROM t_stu left join t_clazz on s.cid = c.cid WHERE s.sid = #{sid} </select >
一条SQL语句,association
两条SQL语句,分步查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <resultMap id ="studentResultMapMyStep" type ="Student" > <id property ="sid" column ="sid" /> <result property ="sName" column ="sname" /> <association property ="clazz" select ="com.huihui.server.mapper.ClazzMapper.SelectByIdStep2" column ="cid" /> </resultMap > <select id ="selectByIdStep1" resultMap ="studentResultMap" > SELECT sid,sname,cid FROM t_stu WHERE s.sid = #{sid} </select > <select id ="selectByIdStep2" resultMap ="Clazz" > SELECT cid,cname FROM t_clazz WHERE cid = #{cid} </select >
分步查询的优点
复用性增强
延迟加载(在用到的时候在去查数据,尽可能的少查以提高性能)
开启延迟加载的两种方式:
association中加入fetchType=”lazy”
在Mybaits的配置文件settings中设置lazyLoadingEnabled = true (实际开发中一般用这种,对于某个不用的设置fetchType=”eager”)
1 2 3 4 5 6 7 8 <resultMap id ="studentResultMapMyStep" type ="Student" > <id property ="sid" column ="sid" /> <result property ="sName" column ="sname" /> <association property ="clazz" select ="com.huihui.server.mapper.ClazzMapper.SelectByIdStep2" column ="cid" fetchType ="lazy" /> </resultMap >
一对多映射
1 2 3 4 5 6 7 8 9 10 11 12 <resultMap id ="clazzResultMap" type ="Clazz" > <id property ="cid" column ="cid" /> <result property ="cname" column ="cname" /> <collection property ="studentList" ofType ="Student" > <id property ="sid" column ="sid" /> <result property ="sName" column ="sname" /> </collection > </resultMap > <select id ="selectByCollection" resultMap ="clazzResultMap" > SELECT cid,cname FROM t_clazz WHERE cid = #{cid} </select >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <resultMap id ="sclazzResultMap" type ="Clazz" > <id property ="cid" column ="cid" /> <result property ="cname" column ="cname" /> <association property ="studentList" select ="com.huihui.server.mapper.StudentMapper.SelectByIdStep2" column ="cid" /> </resultMap > <select id ="selectByIdStep1" resultMap ="clazzResultMap" > SELECT cid,sname FROM t_clazz WHERE cid = #{cid} </select > <select id ="selectByIdStep2" resultMap ="Student" > SELECT sid, cid,cname FROM t_cstu WHERE cid = #{cid} </select >
多对多映射 分解成两个一对多,再来一个一对一
Mybatis缓存 缓存机制:执行DQL(SELECT语句时,将查询结果放到缓存中,如果下次还执行完全相同的DQL语句,则直接从缓存中拿数据)
注:缓存机制只针对DQL语句
Mybatis的缓存
一级缓存(将查询到的数据放到SqlSession中) 一级缓存默认开启
二级缓存(将查询到的数据放到SqlSessionFactory中) 核心文件中默认开启,但其他地方需要配置
在使用二级缓存的mapper文件中加上cache中可以有多种属性可以配置
使用二级缓存的实体类必须是可序列化的,即实现java.io.Serializable接口
只有一级缓存关闭时才会把一级缓存的数据放到二级缓存
SqlSession(范围比较小,只针对当前的sql会话) SqlSessionFactory(范围更大,对于整个数据库而言)
那么什么是SqlSession和SqlSessionFactory呢?
SqlSession和SqlSessionFactory SqlSession(范围比较小,只针对当前的sql会话) SqlSessionFactory(范围更大,对于整个数据库而言)
缓存失效的情况 在第一次和第二次DQL之间做以下两种情况中的一种就会让让一级缓存 失效:
执行了sqlsession的clearCache()方法
执行了insert delete 或 update语句,不管是操作哪张表都会清空缓存
二级缓存 失效:
只要两次查询操作之间出现增删改就会失效
第三方缓存 mybatis除了自带的一级缓存和二级缓存外还可以集成第三方缓存,替代的是自带的二级缓存,一级缓存不会被替代;